只需一步,快速开始
您需要 登录 才可以下载或查看,没有账号?立即注册→加入我们
使用道具 举报
Ayala 发表于 2018-9-29 19:04 临界区的锁还分执行锁、读锁、写锁,获取锁的公平性可以用线程的局部储存来调整线程获取到锁定优先级或者干 ...
tangptr@126.com 发表于 2019-6-17 16:25 随口扯一句pause指令。 在使用硬件虚拟化的虚拟机里pause指令会引起VM-Exit(虚拟机退出执行,由虚拟机软件 ...
0xAA55 发表于 2019-6-17 16:45 这相当于如果虚拟机内的软件pause了,它其实相当于去执行主机上的任务了,相当于某种yield。 这不禁令人 ...
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
|Archiver|小黑屋|技术宅的结界 ( 滇ICP备16008837号 )|网站地图
GMT+8, 2026-6-1 12:15 , Processed in 0.040608 second(s), 26 queries , Gzip On.
Powered by Discuz! X3.5
© 2001-2026 Discuz! Team.

 |Archiver|小黑屋|技术宅的结界
( 滇ICP备16008837号 )|网站地图
|Archiver|小黑屋|技术宅的结界
( 滇ICP备16008837号 )|网站地图
 发表于 2018-9-29 18:12:33
发表于 2018-9-29 18:12:33

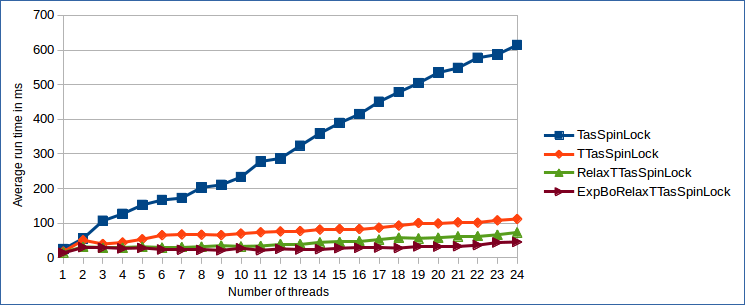
 发表于 2018-9-29 18:49:33
发表于 2018-9-29 18:49:33

 发表于 2018-9-29 19:04:29
发表于 2018-9-29 19:04:29

 发表于 2019-6-17 16:25:47
发表于 2019-6-17 16:25:47